Видео с ютуба Kv Cache Disk

Кэш KV за 15 мин

How to make LLMs fast: KV Caching, Speculative Decoding, and Multi-Query Attention | Cursor Team
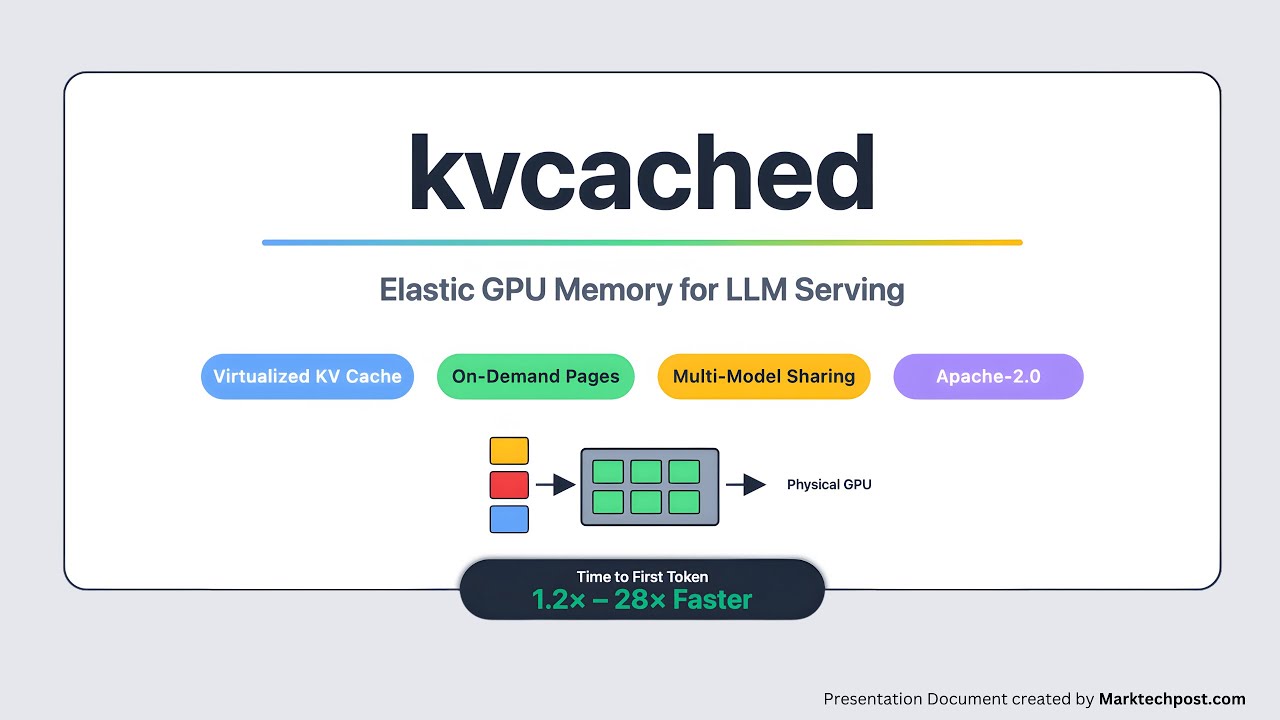
Meet kvcached (KV cache daemon): a KV cache open-source library for LLM serving on shared GPUs

KYAI POD: KV Cache offloading improves TTFT + Claude MCP w/ Nano banana 2

Как кэш ключ-значение влияет на производительность ИИ: Solidigm объясняет скрытый путь каждого за...

Progressi su DeepSeek v4: KV cache su disco

oMLX vs Ollama: Extreme Context, SSD KV Cache & Mac Crashes

LMCache + vLLM: How to Serve 1M Context for Free
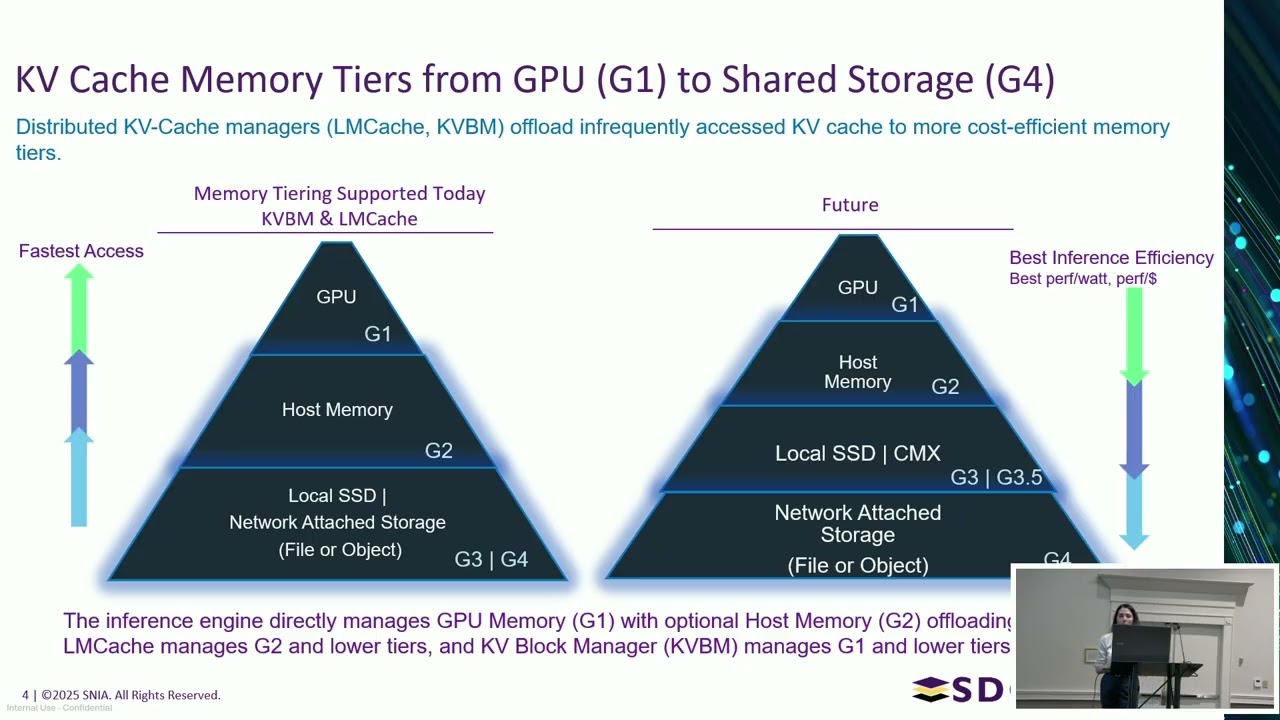
SNIA SDCStorageAI 2026 — Масштабирование вывода с использованием разгрузки кэш-памяти ключ-значен...

KV Cache Acceleration of vLLM using DDN EXAScaler

Breaking Memory Barriers: How KV Cache & DiskANN Optimizations Unlock Scalable AI Video Analytics

LMCache Solves vLLM's Biggest Problem

#HWIDI 2025-Optimizing Scalable LLM Inference-System Strategies for Proactive KV Cache Mgmt-Chen Lei

AI's Real Bottleneck: Storage, HBM, DRAM, NAND and SSDs

Let's Speed up LOCAL AI, OpenClaw & Coding Agents | Batch Caching Explained

HiFC: высокоэффективный обмен кэшем KV на основе Flash для масштабирования вывода LLM

LLMs on Kubernetes: Squeeze 5x GPU Efficiency With Cache, Route, Repea... Yuhan Liu & Suraj Deshmukh

KV Cache Explained | AI Infra Deep Dive | OpenAI & Anthropic Interview Favorite

Tactical Sports Analytics at Scale with Solidigm KV Cache Offload

Optimizing Transformer Models with KV Cache and Trie Indexing